THE_IDEA
What if you could embed a hidden message into an audio file? One that's completely inaudible to human ears, but that an AI speech-to-text model like OpenAI's Whisper would confidently transcribe.
And what if you could flip that around? Add a subtle layer of noise to your voice recordings that makes them untranscribable, effectively anonymizing your speech against automated surveillance.
That's Vox Inanis (Latin for "Voice of the Void"). A research toolset exploring both sides of adversarial audio: injection (forcing a model to hear a target phrase) and disruption (preventing a model from transcribing anything useful).
WHAT_IT_DOES
Vox Inanis uses gradient-based adversarial attacks against OpenAI's Whisper model. It takes any piece of audio (speech, music, ambient noise) and computes a tiny perturbation that changes what Whisper transcribes when added to the original signal.
The perturbation is bounded. Each audio sample can change by at most a fraction of a percent, controlled by an L∞ budget (typically 3-5% of full scale). To human ears, the audio sounds identical. To Whisper, it says something completely different.
TARGETED INJECTION
Force Whisper to transcribe a specific phrase. Feed in a 22-second job interview recording and Whisper outputs "hello world!" instead of the actual speech. The original words are gone. Only the injected payload remains.
ADVERSARIAL ANONYMIZATION
The inverse problem. Instead of injecting a specific phrase, the perturbation is optimized to maximize transcription error. Whisper produces garbled nonsense, random tokens, or nothing at all. Your voice is effectively anonymized against any downstream STT pipeline.
Both modes produce audio that sounds identical to the original when played back through speakers. The changes exist purely in the statistical patterns that neural networks rely on.
RELATED_WORK
Adversarial attacks on neural networks have been studied extensively in the image domain since Szegedy et al. (2013) and Goodfellow et al.'s Fast Gradient Sign Method (2014). Vox Inanis builds on several lines of prior work in audio:
"Audio Adversarial Examples" Demonstrated that targeted adversarial examples against DeepSpeech are feasible by optimizing directly over the raw waveform. Established the basic paradigm of minimizing CTC loss with an L∞ constraint. Vox Inanis adapts this approach to Whisper's encoder-decoder architecture and cross-entropy loss.
Schönherr et al., 2019"Adversarial Attacks Against ASR via Psychoacoustic Hiding" Introduced perceptual masking into adversarial audio attacks, using psychoacoustic models to push perturbation energy into frequency bands where the human ear is least sensitive. My STFT-domain masking loss is a simplified variant of this idea.
Madry et al., 2018"Towards Deep Learning Models Resistant to Adversarial Attacks" Formalized Projected Gradient Descent (PGD) as the canonical first-order adversarial attack. My sign-PGD optimizer with L∞ projection follows this framework directly.
Dong et al., 2018"Boosting Adversarial Attacks with Momentum" Proposed MI-FGSM, which adds momentum to the gradient update to escape poor local optima and improve transferability. I use MI-FGSM with a decay factor of 0.9 as the default optimizer.
Athalye et al., 2018"Obfuscated Gradients Give a False Sense of Security" Demonstrated that defenses relying on non-differentiable transformations can be bypassed using the Straight-Through Estimator (STE). My codec-in-the-loop training uses the same STE trick: forward pass runs the real ffmpeg AAC codec, backward pass treats it as identity.
Yakura & Sakuma, 2019"Robust Audio Adversarial Example for a Physical Attack" Showed that audio adversarial examples can survive over-the-air playback using band-pass filtering and impulse response simulation during optimization. My codec-in-the-loop approach applies the same principle to digital lossy compression rather than physical channel effects.
To my knowledge, Vox Inanis is the first open implementation that combines MI-FGSM optimization, STFT-domain perceptual masking, and codec-in-the-loop training with a Straight-Through Estimator in a single pipeline targeting Whisper's encoder-decoder architecture.
THREAT_MODEL
ATTACKER MODEL
Whitebox access to one or more Whisper checkpoints (full gradient access through the frozen model). Compute budget for per-input PGD optimization (~30s to a few minutes on a consumer GPU). Knowledge of the target STT model family and its expected language. No access to the deployed downstream system, no real-time capability, no arbitrary query access assumed.
TARGET PIPELINE
The attack targets the transcription step of a pipeline: (1) audio capture/upload, (2) optional codec round-trip (YouTube AAC at 128 kbps), (3) STT model producing transcript, (4) optional downstream LLM consuming transcript. The perturbation lives in step 1. Survival through step 2 is a design goal. Manipulation of step 4 via injected tokens is the natural downstream threat but is not directly evaluated here.
PERTURBATION CONSTRAINTS
Must be audibly transparent (L∞ budget + STFT masking). Must be self-contained (sample-aligned additive signal, no side-channel needed for decoding). Must be codec-robust (survive AAC at 128 kbps / 44.1 kHz).
SCOPE LIMITATIONS
Mono audio only. Audio ≤ 30 seconds (Whisper's encoder context limit). Per-audio whitebox optimization (no real-time or universal perturbations yet). Evaluated on English and German, not systematically across all 99 Whisper languages.
METHODOLOGY
DIFFERENTIABLE WHISPER
Whisper's model.transcribe() API is not differentiable. It performs autoregressive beam search with discrete token selection. I bypass it and call the encoder and decoder directly:
audio (16 kHz mono, len ≤ 30s)
→ whisper.audio.pad_or_trim
→ whisper.audio.log_mel_spectrogram // differentiable STFT + mel + log
shape: (1, n_mels, 3000)
→ model.encoder // frozen transformer
shape: (1, 1500, n_audio_state)
→ model.decoder(input_ids, audio_features)
→ logits, shape (1, S, vocab)
→ cross-entropy loss vs. target tokens
→ backpropagate gradients to raw audio samplesThe log_mel_spectrogram function is pure PyTorch ops (STFT, matmul, log, clamp), so gradients flow through it. The encoder and decoder are frozen (requires_grad=False on every parameter). Only the input audio waveform accumulates gradient. I'm not training the model. I'm training the input.
FORCED-PREFIX DECODING
Whisper's decoder is conditioned on a prefix of special tokens that select language and task: [<|startoftranscript|>, <|language|>, <|transcribe|>, <|notimestamps|>]. I feed the full sequence [prefix, target_tokens] to the decoder and compute cross-entropy only on the content positions. Standard teacher-forcing loss restricted to the positions that matter.
Language sensitivity is critical. The attack optimizes against a specific language prefix token. If validation uses Whisper's auto-language-detection and the detected language differs from the attack language, the attack fails silently. Whisper decodes with a different prefix and never enters the high-probability region the optimizer found.
MI-FGSM OPTIMIZER
I use MI-FGSM (Momentum Iterative Fast Gradient Sign Method) with L∞ projection:
// Normalize current gradient by L1 mean (stabilizes across steps) grad_norm = grad / (grad.abs().mean() + 1e-12) // Accumulate with momentum (decay = 0.9) grad_momentum = 0.9 * grad_momentum + grad_norm // Sign-step with cosine-scheduled learning rate delta = delta - effective_lr * grad_momentum.sign() // Project back into L-inf epsilon-ball delta = delta.clamp(-eps, eps)
The cosine learning rate schedule decays from lr_max to lr_min over the run. Large steps early for exploration, small steps late for refinement. The perturbation is initialized with uniform random noise within the epsilon-ball rather than at zero, which empirically improves convergence by avoiding symmetric gradient cancellation.
I also apply logit temperature scaling (T = 0.8) to sharpen the decoder's output distribution before computing cross-entropy. This provides stronger gradients early in optimization when the model is still uncertain.
PERCEPTUAL MASKING LOSS
The L∞ constraint bounds peak amplitude but says nothing about audibility. A perturbation spread uniformly across all samples is far more audible than the same energy concentrated where the cover audio is already loud. I enforce perceptual hiding with an STFT-domain masking loss:
cover_mag = |STFT(x)| delta_mag = |STFT(delta)| threshold = cover_mag * 10^(mask_db / 20) masking_loss = mean(ReLU(delta_mag - threshold)^2) L_total = L_CE + lambda * L_mask
The STFT uses a Hann window with n_fft = 1024 and hop length = 256 at 16 kHz, giving 8 ms hop and 64 ms window. At mask_db = -25, the perturbation may be at most ~1/18 of the local cover amplitude in each time-frequency bin. Bins exceeding this threshold contribute quadratic penalty. Bins below contribute zero.
The tradeoff: lambda = 0 gives a pure CE attack (converges fastest, fully audible). Lambda in [10, 200] is the practical range. Lambda = 50 works well for covers with high-entropy texture (noise, music, ambient). Speech with quiet pauses needs higher lambda to keep the silent gaps clean.
CODEC-IN-THE-LOOP (STE)
A perturbation optimized against raw audio will not survive AAC compression at 128 kbps. To produce codec-robust attacks, I route the perturbed audio through ffmpeg inside the optimization loop. ffmpeg has no usable Jacobian, so I wrap it in a Straight-Through Estimator: the forward pass runs the real ffmpeg pipeline (resample to 44.1 kHz, AAC encode, decode, resample back to 16 kHz), the backward pass treats the codec as the identity function.
The STE is mathematically loose (it ignores the codec's actual local behavior) but empirically effective. To make this fast enough for iterative use, I replaced the file-based ffmpeg pipeline with a pipe-based version that streams audio through stdin/stdout, eliminating all disk I/O.
GRADIENT CHECKPOINTING
PGD requires the full backward pass through encoder and decoder. Storing all intermediate activations approximately doubles peak memory vs. inference-only. To run Whisper small (460 MB) on GPUs with limited VRAM, I wrap each transformer block in torch.utils.checkpoint.checkpoint(use_reentrant=False). Activations inside each block are discarded after the forward pass and recomputed during the backward pass. Trades ~1.4x compute for ~3x lower peak memory.
EXPERIMENT
RUN 24EC741A // TARGETED INJECTION ON REAL SPEECH
Cover audio: ElevenLabs-generated speech, 22.52 seconds, 360,281 samples at 16 kHz mono. A mock job interview in German. The speaker introduces themselves, mentions a preference for strong coffee, and describes their approach to complex systems. Fluent, natural German speech with varied prosody and natural pauses.
Target text: "hello world! how are you" (English)
HYPERPARAMETERS
small · 244M params · 460 MBen (forced)LISTEN FOR YOURSELF
The unmodified interview recording in German. Whisper transcribes the full speech correctly.
Listen for the crackling and white noise layer. Whisper now transcribes: "hello world!" instead of the German speech.
After lossy compression. The noise is still present. Whisper outputs: "Yes, my lord, ollh good!" The original German is still gone.
TRANSCRIPTION ACROSS STAGES
“Good day! First of all, thank you for taking the time today. Why am I the right person for this job? Probably not because of my legendary preference for too much strong coffee. But because I see complex systems as a lively puzzle. And I give rest only when every part is perfectly in its place.”
Whisper auto-translates the German speech to English in its output.
"hello world!"
"Yes, my lord, ollh good!"
The clean transcription is accurate and complete. Whisper small has no difficulty with the ElevenLabs voice. After injection, the original 58-word transcript is replaced entirely by the two-word target phrase. After the YouTube codec round-trip, the injected payload degrades to garbled fragments, but the original speech is not recovered. Whisper produces only 6 tokens of nonsensical output.
Current state: The injection works, but it's audible. You can clearly hear crackling and a white noise layer on the perturbed files. The next goal is to push the perturbation further below the audibility threshold and see how invisible I can actually make this.
CONVERGENCE
| Initial CE loss | 5.109 |
| Final CE loss | 0.279 |
| Initial masking loss | 0.298 |
| Final masking loss | 0.278 |
| Initial total loss | 20.028 |
| Final total loss | 14.175 |
SIGNAL METRICS
14.97 dB SNR
Clean-to-perturbed signal-to-noise ratio. The perturbation is audible as crackling/noise at this level. This is what I want to improve.
L∞ = 0.05
Hits exactly the epsilon budget. Each sample moves by at most 5% of full amplitude. The codec increases this to 0.077 as compression smears the perturbation.
322.95s WALL TIME
~5.4 minutes for 300 steps on Apple MPS. About 1.08 seconds per step including forward pass, loss computation, and backpropagation through the full Whisper model.
DIAGNOSTIC VISUALIZATIONS
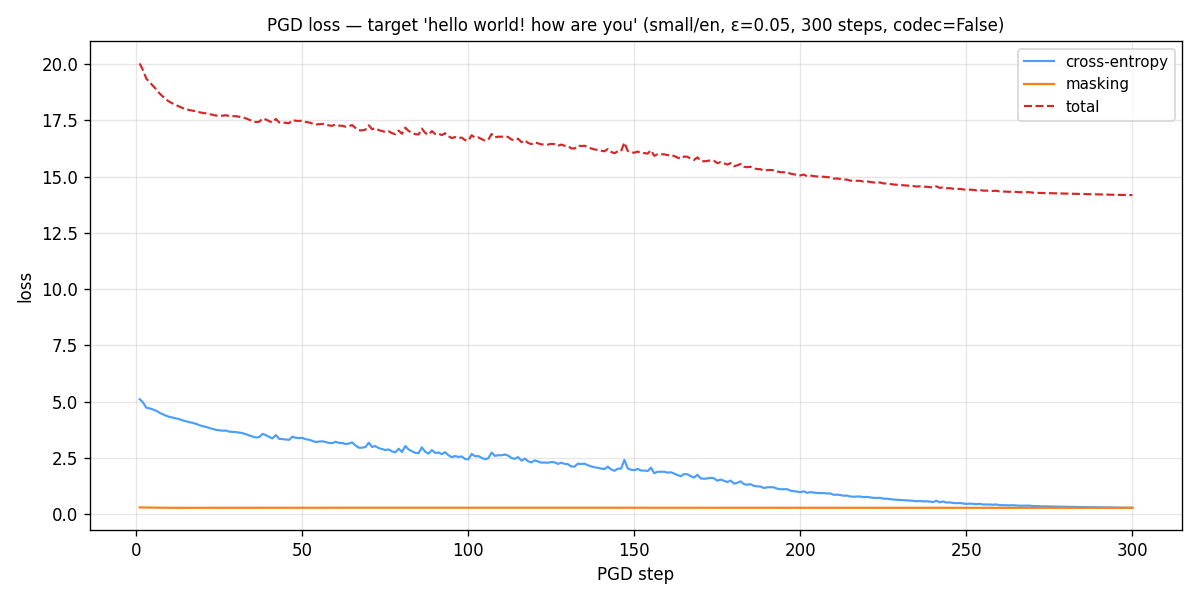 FIG_02 // PGD_LOSS_CURVE
FIG_02 // PGD_LOSS_CURVEThe optimizer's confidence over time. The line dropping means Whisper is becoming more and more certain that the audio says 'hello world' instead of the original German speech.
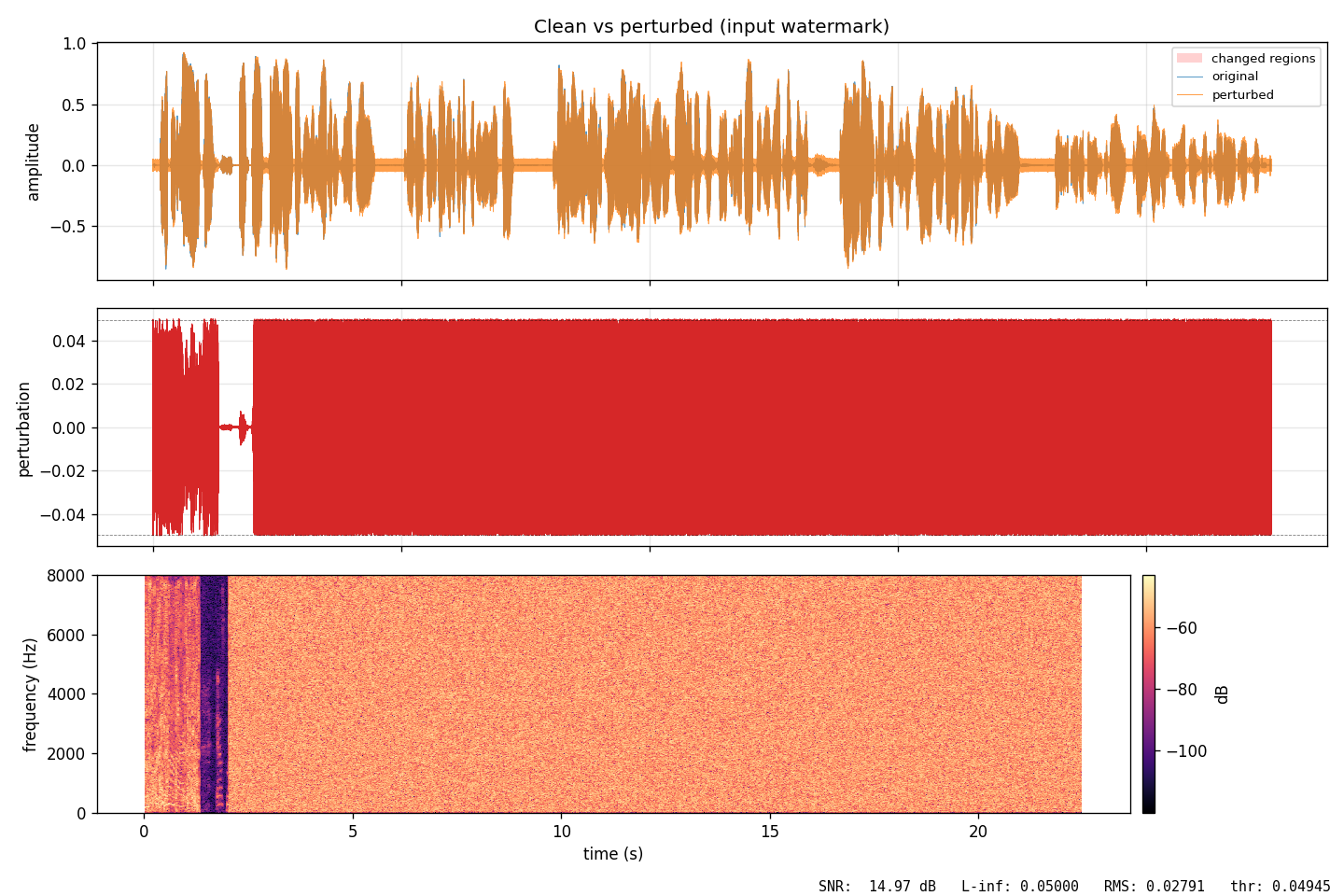 FIG_03 // CLEAN_VS_PERTURBED
FIG_03 // CLEAN_VS_PERTURBEDSide-by-side of original (left) and injected version (right). Waveforms look nearly identical, but the frequency content has shifted in ways only the model notices.
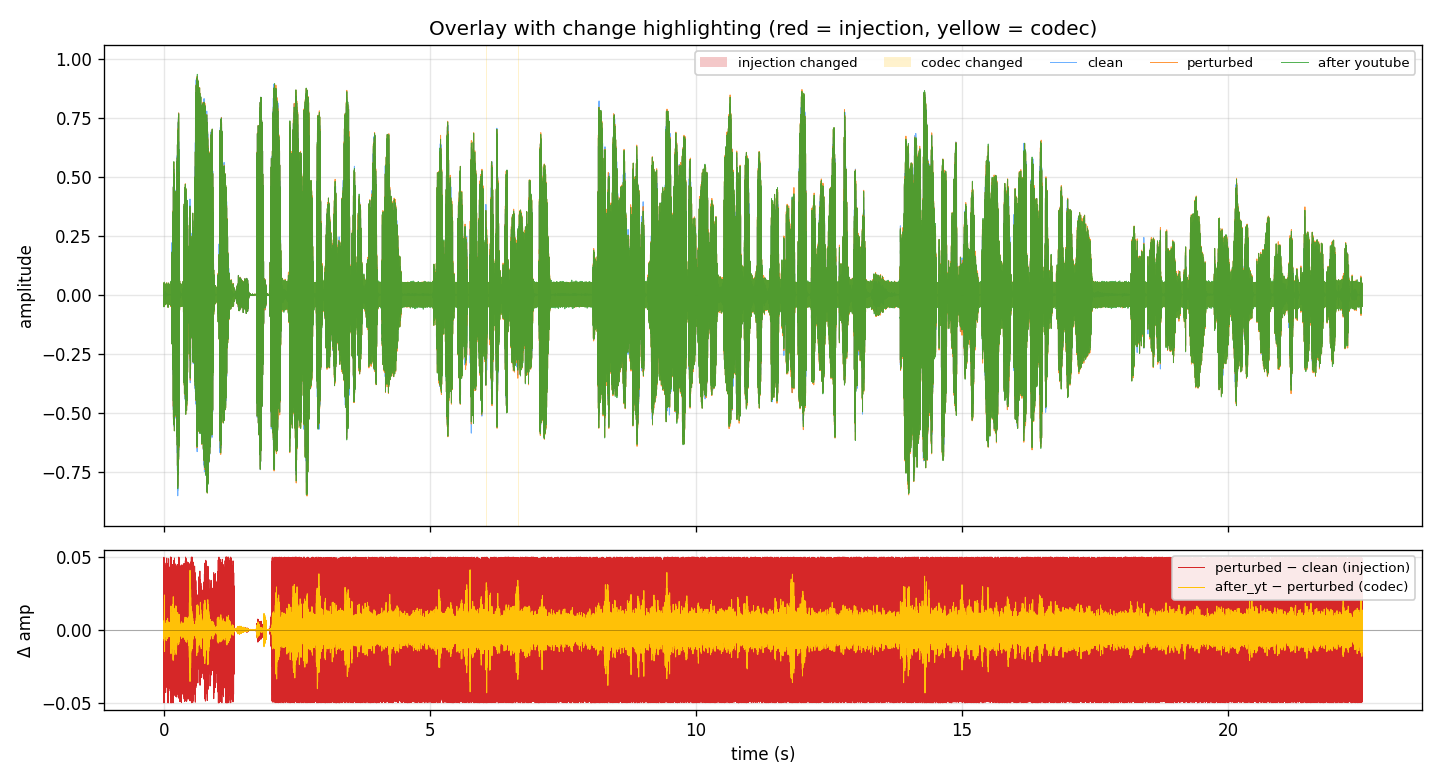 FIG_04 // WAVEFORM_OVERLAY
FIG_04 // WAVEFORM_OVERLAYRed = the injected perturbation, yellow = codec artifacts. The injection is small compared to the original signal but present throughout the entire clip.
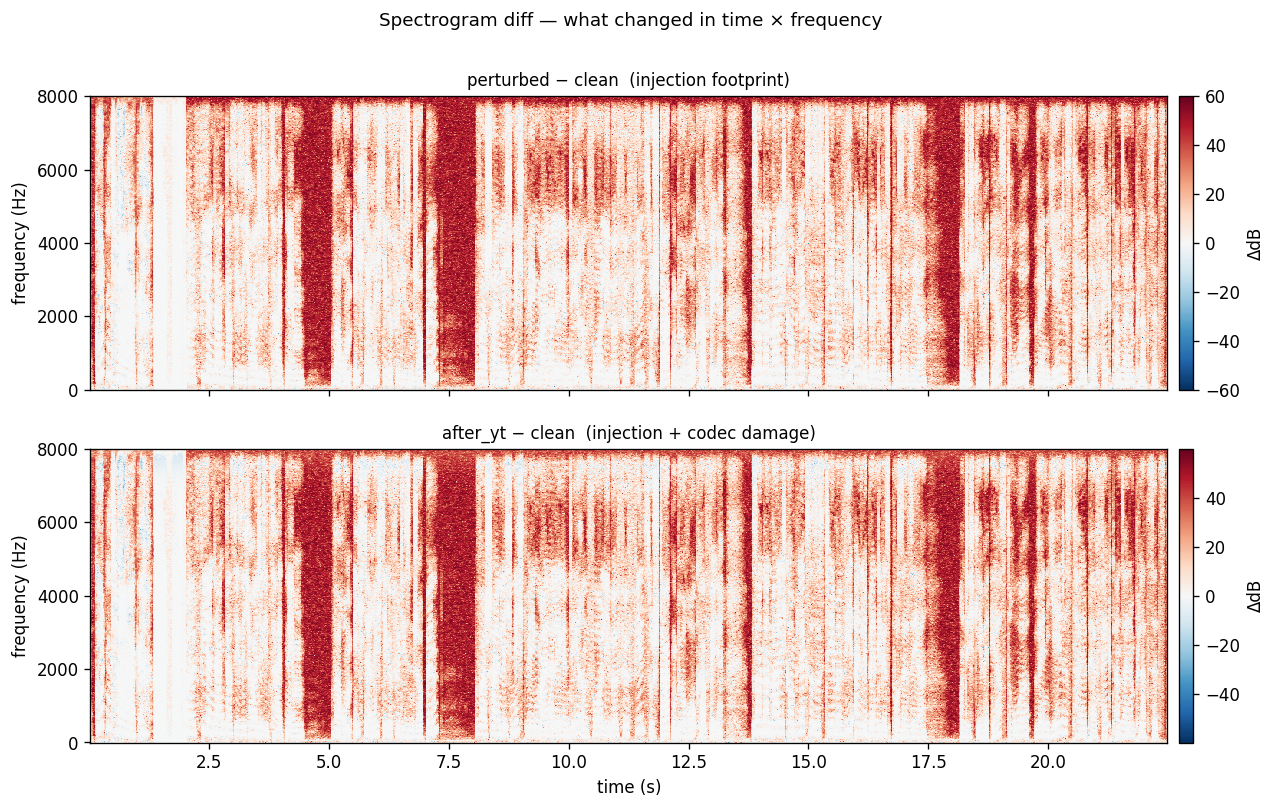 FIG_05 // SPECTROGRAM_DIFF
FIG_05 // SPECTROGRAM_DIFFRed = frequency energy added by the attack, blue = energy removed. The large red block is the white noise you can hear in the perturbed audio. This is what I want to reduce next.
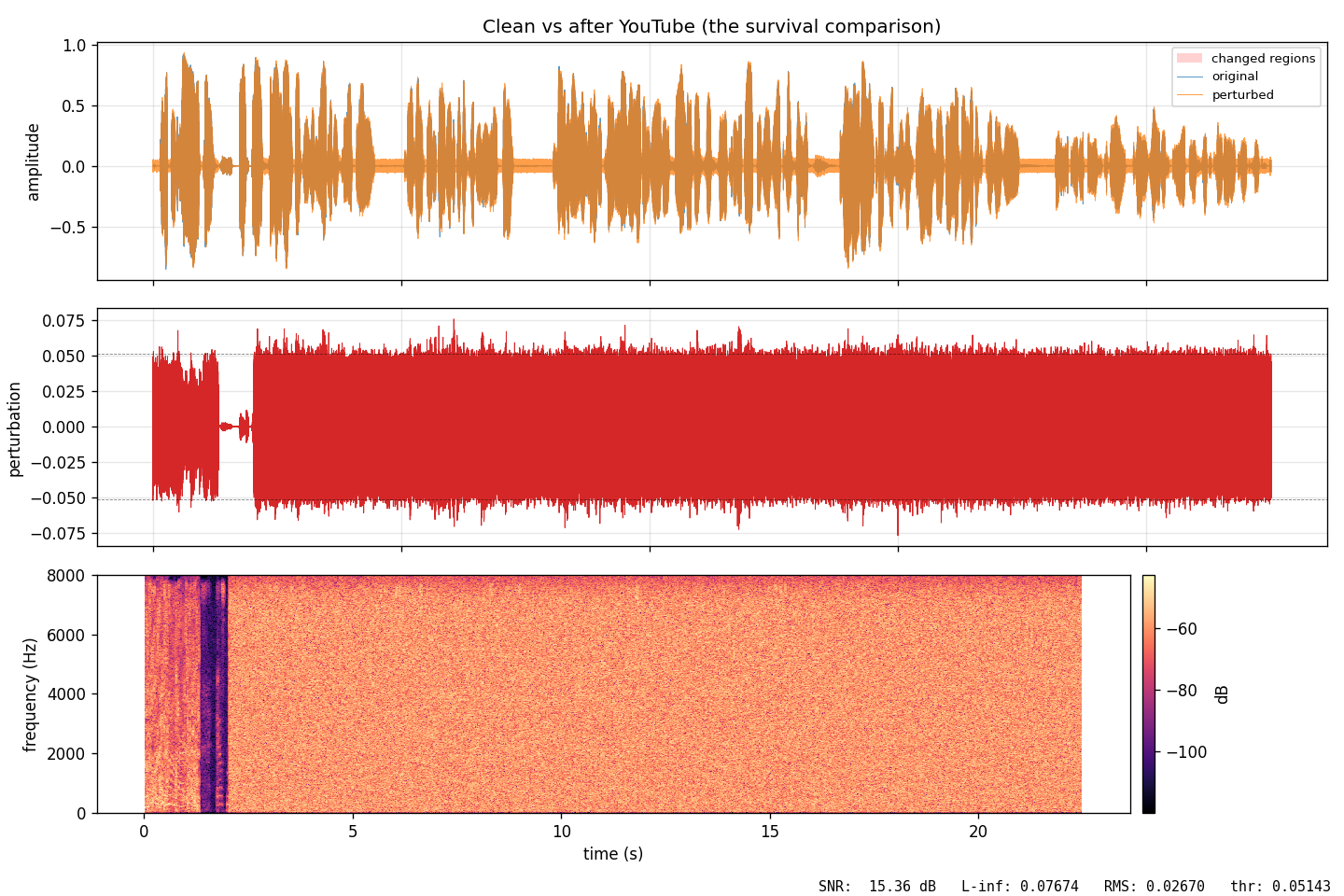 FIG_06 // CODEC_SURVIVAL
FIG_06 // CODEC_SURVIVALCompares original with the version after YouTube's AAC codec. The perturbation is affected by compression but still prevents correct transcription.
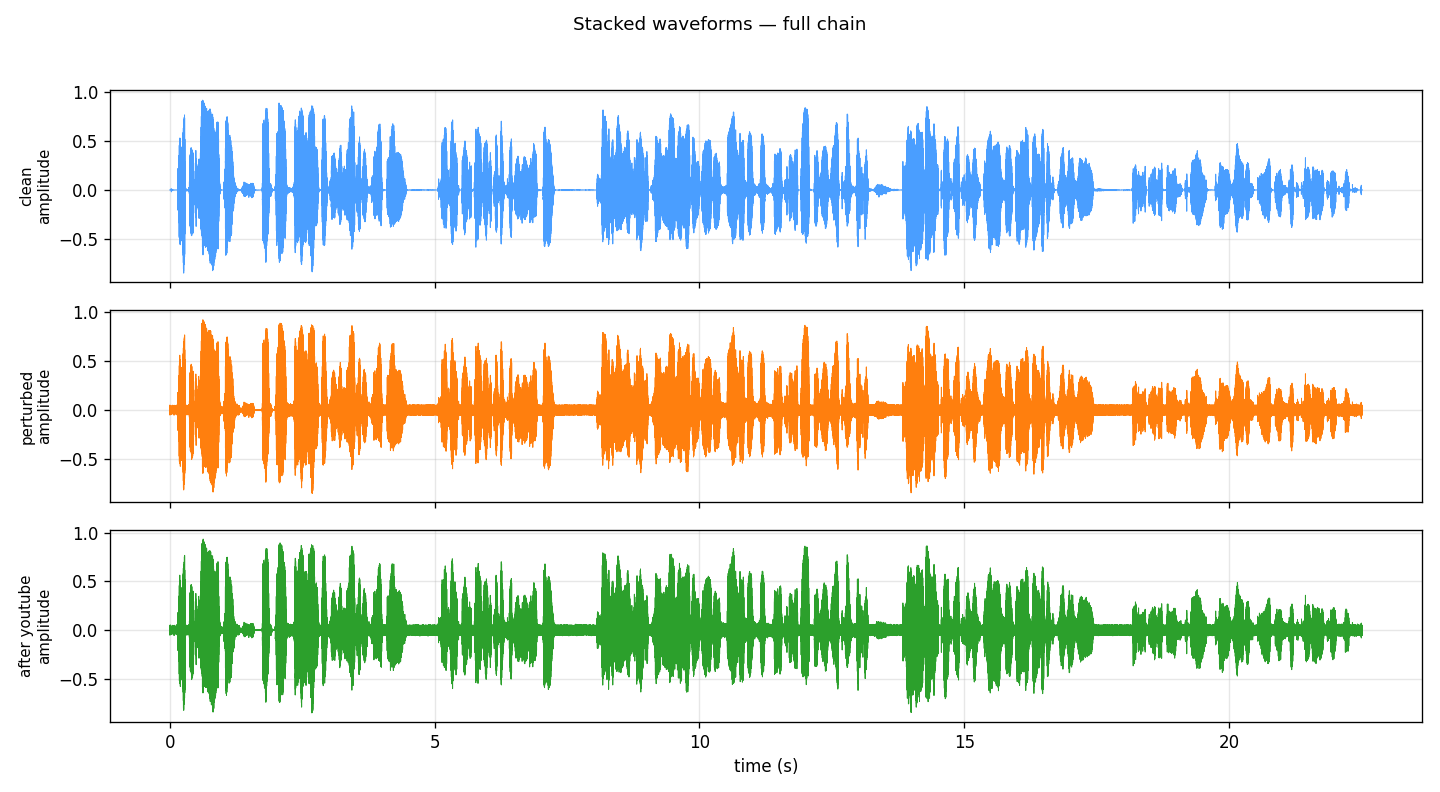 FIG_07 // STACKED_WAVEFORMS
FIG_07 // STACKED_WAVEFORMSAll three versions stacked. Top = original, middle = after injection, bottom = after YouTube codec. Waveforms look almost identical to the eye.
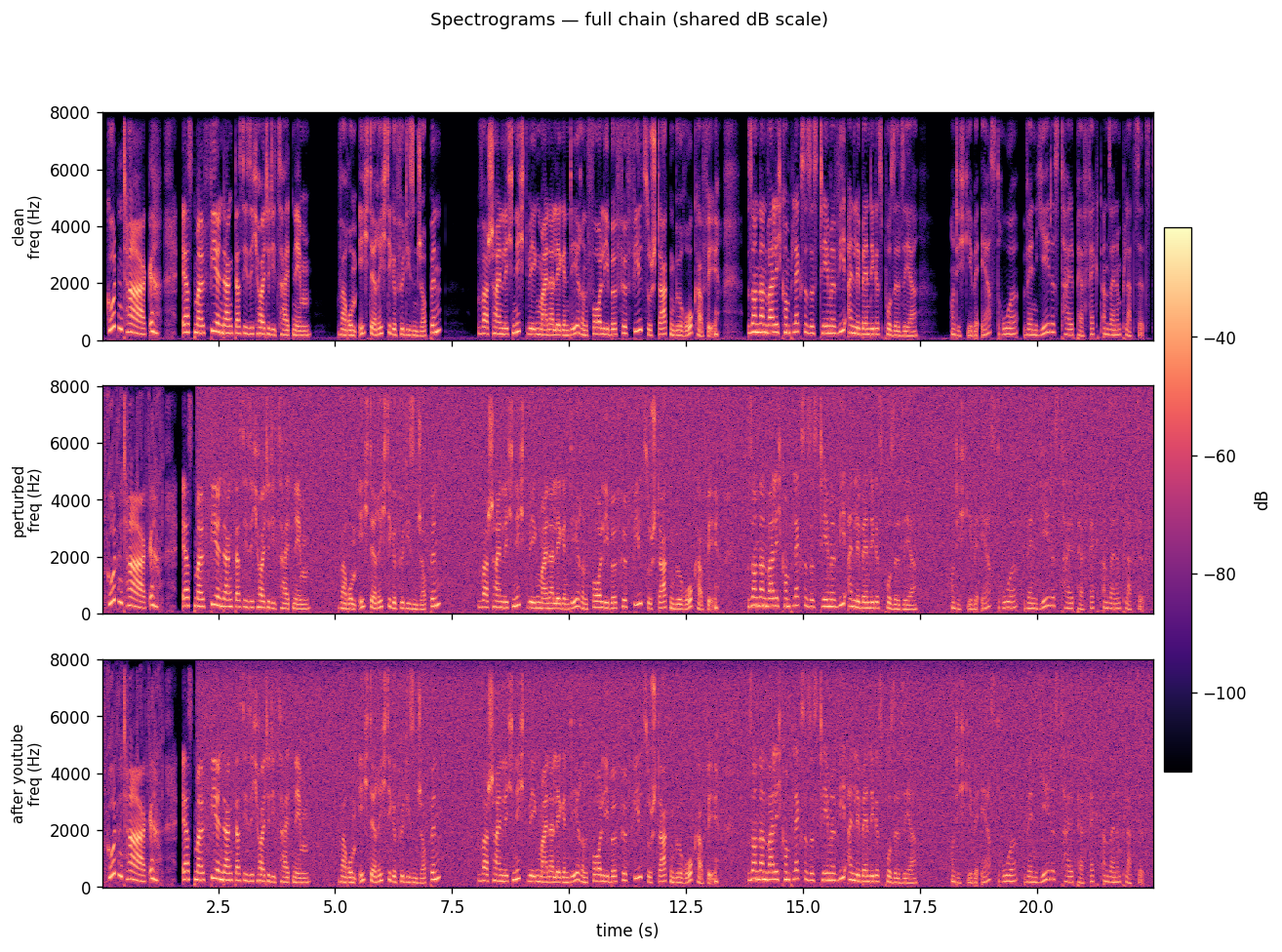 FIG_08 // THREE_SPECTROGRAMS
FIG_08 // THREE_SPECTROGRAMSFrequency content over time for all three versions. The spectrograms show which parts of the frequency spectrum are active at each moment. Differences here are what Whisper picks up on.
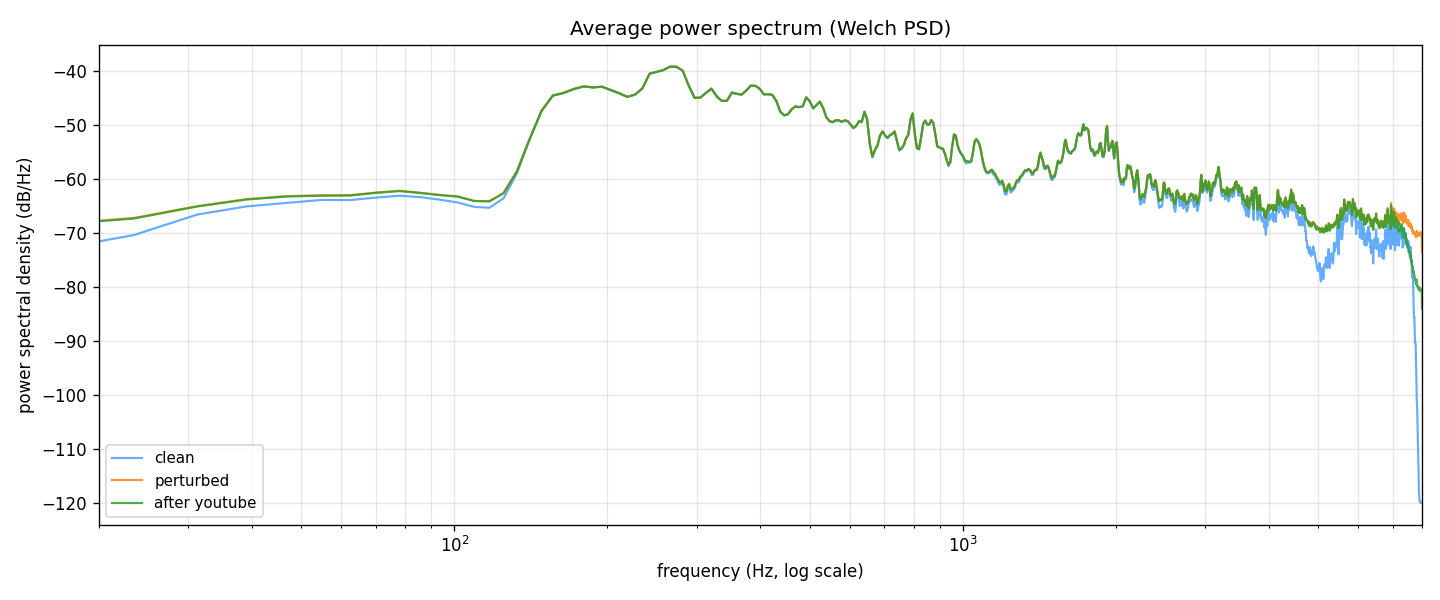 FIG_09 // POWER_SPECTRAL_DENSITY
FIG_09 // POWER_SPECTRAL_DENSITYPower distribution across frequencies. The perturbation adds energy mostly in mid-to-high frequencies where it's harder for humans to notice, but still clearly visible as the gap between the lines.
KEY FINDING: DISRUPTION SURVIVES THE CODEC
The target phrase "hello world! how are you" did not survive the YouTube codec. The perturbed-stage transcription hits the target, but the after-YouTube transcription produces "Yes, my lord, ollh good!" instead.
However, the original speech was not recovered either. The 128 kbps AAC round-trip destroyed the precise adversarial pattern that encoded the target phrase, but it also destroyed the cover audio's original statistical features that Whisper relied on for accurate transcription. The result is complete transcript annihilation: neither the target phrase nor the original speech survives.
This has direct implications for the defensive use case. An adversarial perturbation optimized for injection also functions as a disruption tool, even when the injection itself fails. The codec strips the payload but leaves the damage.
ADVERSARIAL_ANONYMIZATION
Every voice recording you make (video calls, voice messages, podcast appearances, ambient audio from smart devices) can be fed into STT models and transcribed without your knowledge or consent. The resulting text is searchable, indexable, and permanent. Your spoken words become data.
Run 24ec741a was designed as a targeted injection experiment, but its after-codec result demonstrates the anonymization principle empirically: the perturbation completely prevented Whisper from recovering the original 58-word interview transcript, even after lossy compression stripped the injected payload. What remains is 6 tokens of garbled nonsense.
UNTRANSCRIBABLE
Whisper (and likely other STT models) cannot recover your words. The audio sounds normal to human listeners.
CODEC-ROBUST
The disruption survives lossy compression. YouTube, podcast hosting, messaging apps. No cooperation from the platform required.
CLIENT-SIDE
Apply the perturbation before upload. No server-side integration needed. Works with any existing audio pipeline.
ACOUSTIC CAMOUFLAGE
Your voice passes through to human ears unchanged, but the machine listening layer sees only noise. Dazzle camouflage for the audio domain.
NOTE: Dedicated anonymization experiments (untargeted disruption, entropy maximization) have not yet been run. The anonymization finding here is inferred from the injection experiment's after-codec behavior. Systematic evaluation with WER measurements is planned.
DEFENSE_CONSIDERATIONS
Any responsible publication of attack capabilities must be paired with defense analysis. The following defenses are under investigation:
D1 // INPUT DETECTION
Flag adversarial structure before the audio reaches STT. Spectral residuals, statistical anomalies in windowed sample distributions, or a learned classifier trained on (clean, perturbed) pairs from my own attack runs.
D2 // DEFENSIVE RE-ENCODING
Apply lossy processing (8-bit quantization, additional codec round-trip, low-pass filtering) to destroy adversarial features before transcription. The mirror of why my attacks need codec-in-the-loop training.
D3 // RANDOMIZED SMOOTHING
Apply random small perturbations of the same magnitude as epsilon at inference time and average transcriptions over multiple samples. Classic adversarial robustness technique from the image domain.
D4 // PROMPT HARDENING
If the threat is "STT emits attacker-controlled tokens, LLM acts on them," the LLM side can defend by treating transcripts as untrusted input. Explicit framing, output format constraints, or two-stage classification.
D5 // ADAPTIVE EVALUATION
A defense evaluated only against the original non-adaptive attack is overestimated (Athalye, Tramer, Carlini 2018). Real-world deployment must assume the attacker adapts to whatever defense is deployed.
STATUS
All defense evaluations are currently stubs. No quantitative defense measurements have been taken yet. This is next on the roadmap after the ablation sweeps.
OPEN_QUESTIONS
CROSS-MODEL TRANSFER
Do perturbations optimized against Whisper small transfer to Whisper large? To completely different STT engines like Vosk, Google Speech-to-Text, or Azure?
MINIMUM DETECTABLE PERTURBATION
How small can epsilon be before an input-side anomaly detector (that doesn't run STT) can reliably flag the audio as adversarial?
WORD ERROR RATE
Current evaluation is boolean: hit or miss on the target phrase. Proper WER measurement against the clean transcript is needed for quantitative claims.
ABLATION STUDIES
Systematic sweeps over epsilon (0.01, 0.03, 0.05, 0.08), lambda (0, 10, 50, 100, 200), and optimizer (sign-PGD vs. MI-FGSM vs. Adam) to map the parameter space.
CODEC-IN-LOOP VS. POST-HOC
Does enabling codec-in-the-loop during optimization produce post-codec target hits? Or does the after-codec result always degrade to garbled output?
PERCEPTUAL QUALITY
ABX listening tests to rigorously measure human-perceived audio quality degradation across different playback conditions and listener populations.
SANDBOX_UI
Vox Inanis ships with an interactive web interface for experimenting with attacks in real-time. Built on FastAPI with server-sent events for live progress streaming.
Upload any audio clip or generate synthetic pink noise. Configure all attack parameters (epsilon, optimizer, masking depth, codec simulation). Watch the PGD loss converge in real-time. Compare clean vs. perturbed vs. post-codec audio side by side. Inspect 8 diagnostic visualizations per run. Runs on Apple Silicon MPS or CUDA, completing in about 5 minutes for a 22-second clip at 300 steps.
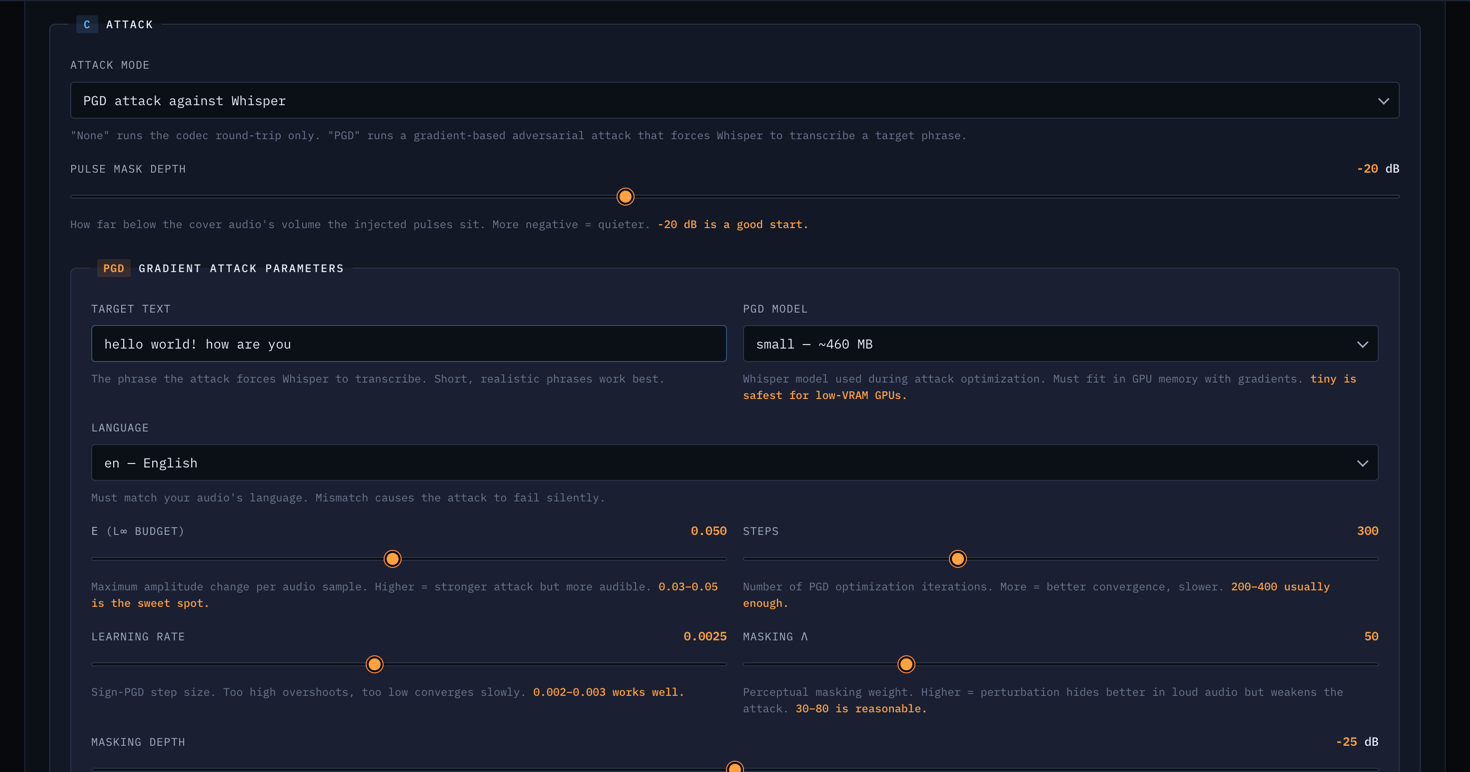 FIG_10 // ATTACK_CONFIG
FIG_10 // ATTACK_CONFIGThe attack configuration panel. Set target text, choose Whisper model size, adjust epsilon budget, masking parameters, and codec simulation options.
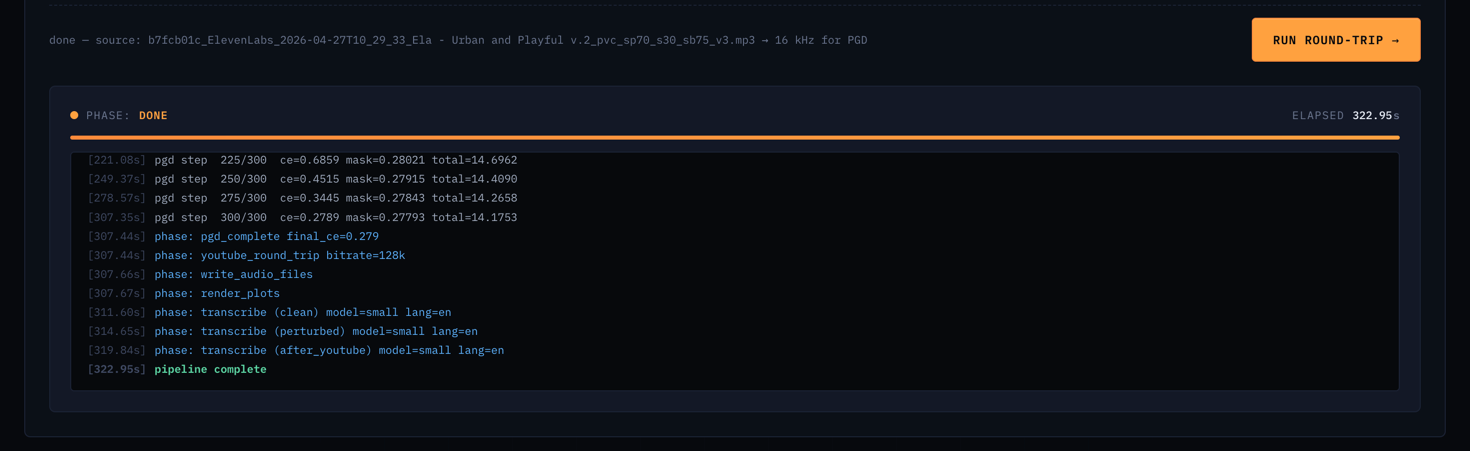 FIG_11 // LIVE_WORKFLOW
FIG_11 // LIVE_WORKFLOWThe live optimization view. Each of the 12 pipeline phases streams its status in real-time via server-sent events as the attack progresses.
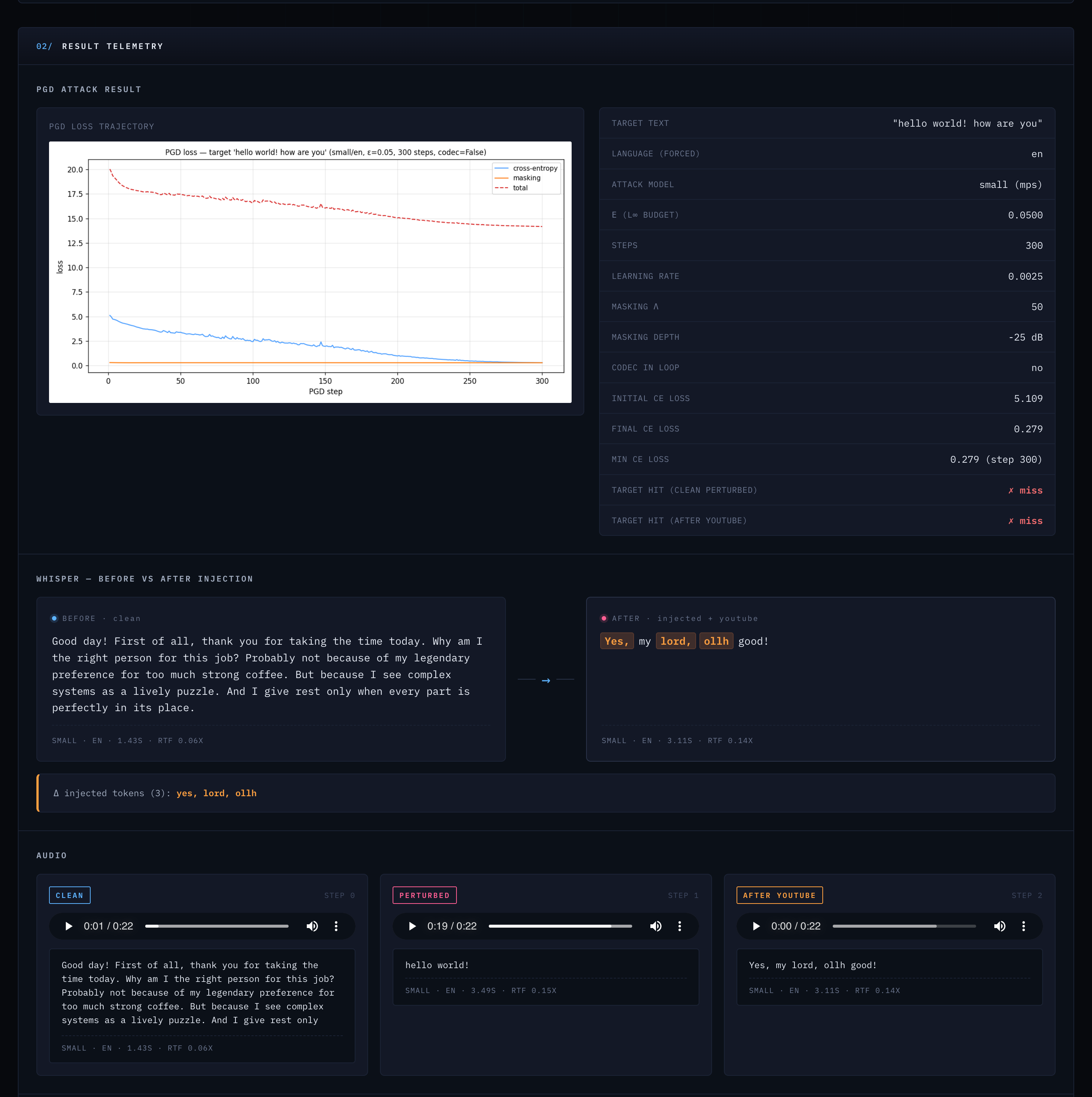 FIG_12 // RESULTS_VIEW
FIG_12 // RESULTS_VIEWThe results panel after a completed run. Shows Whisper transcriptions at each stage (clean, perturbed, after codec) with side-by-side comparison and signal metrics.
 FIG_13 // FULL_INTERFACE
FIG_13 // FULL_INTERFACEThe complete Vox Inanis interface showing the diagnostic visualization gallery with waveform overlays, spectrogram diffs, and loss curves generated per run.
TECH_STACK
WHATS_NEXT
REDUCE AUDIBILITY
The current perturbation is audible as crackling and white noise. Push it further below the audibility threshold. The spectrogram diff (FIG_05) shows the target: shrink that red block.
ANONYMIZATION MODE
Implement untargeted disruption (entropy maximization) and measure WER degradation systematically. Currently inferred from injection results only.
ABLATION SWEEPS
Systematic parameter grid searches over epsilon (0.01-0.08), lambda (0-200), and optimizer (sign-PGD vs. MI-FGSM vs. Adam). Persist metadata per run for reproducible results tables.
CODEC-IN-LOOP TEST
Compare target survival rates with and without codec-in-the-loop training enabled. Does it produce post-codec target hits?
BLACKBOX TRANSFER
Test whether perturbations optimized against Whisper also fool other STT engines. Google Speech-to-Text, Vosk, Azure.
LIVE ANONYMIZATION
Real-time audio filter that adversarially perturbs your microphone output before it reaches any recording or transcription system. Requires the generator network from real-time streaming.
TAKEAWAYS
Building Vox Inanis taught me that the boundary between "what humans hear" and "what machines hear" is surprisingly thin, and exploitable in both directions. A perturbation smaller than background noise can completely rewrite a transcript. The same technique that enables injection also enables defense.
The adversarial ML literature is full of image-domain attacks, but audio is a different beast. The signal is one-dimensional, the relevant features live in the frequency domain, and real-world deployment means surviving lossy compression. Making all of this differentiable (including the codec) was the core engineering challenge.
The most surprising finding from this phase was not that the injection worked. It was that the disruption survived the codec even when the injection didn't. That accident points toward the most impactful application: not putting words in Whisper's mouth, but taking them away.
DISCLAIMER: Vox Inanis is a research project for evaluating adversarial robustness of speech-to-text models. Attack payloads are constrained to owner-ID format strings. The codebase enforces strict isolation between research and production paths. Responsible disclosure guidelines apply to all findings.